How to Build an MVP with AI: From Idea to Deployed in One Sitting (2026)
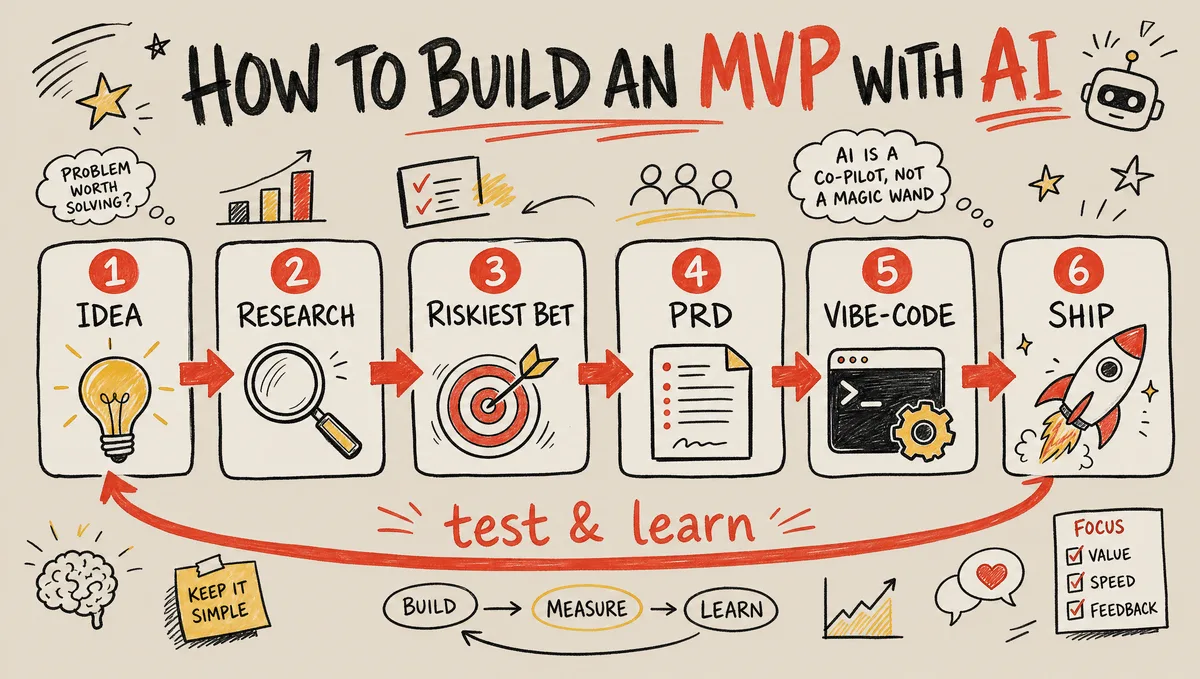
You don't start by building. You start by finding the one assumption that would kill the idea, then build the smallest thing that tests it. Here's the full idea-to-deployed workflow from a live AI build session: research the market with ChatGPT, pick a segment on unit economics, have AI write the PRD, then vibe-code and ship with Claude Code — in a couple of hours, not a quarter.
This workflow is from a live MVP build by product strategist Ivan Zamesin, who took a maker's raw idea — an AI-photoshoot app — from a single sentence to a deployed, payment-wired MVP in about two hours. This is the maker's cut: the repeatable steps, the actual prompts, and the tool choices, reframed so you can run the same loop on your own idea. The point of the demo was never the photoshoot app. It was to test the riskiest assumption as fast as possible — and that reframe is the whole game.
How do you build an MVP with AI?
Building an MVP with AI is one loop run end to end: turn a one-line idea into a researched bet, find the assumption most likely to kill it, have AI write the spec, then vibe-code and ship the smallest thing that tests that one assumption. The model does the typing — the market research, the product requirements, and the code. Your job is the judgment between the steps: which segment, which risk, what to cut.
The order matters more than the speed. Most people open a code tool first and end up with a beautiful app nobody wants. The loop below front-loads the thinking AI is good at helping with — research and risk — so that by the time you write a line of code, you already know exactly what you're trying to prove. Run it on a weekend; the demo it's based on ran in about two hours.
What should you do before you write any code?
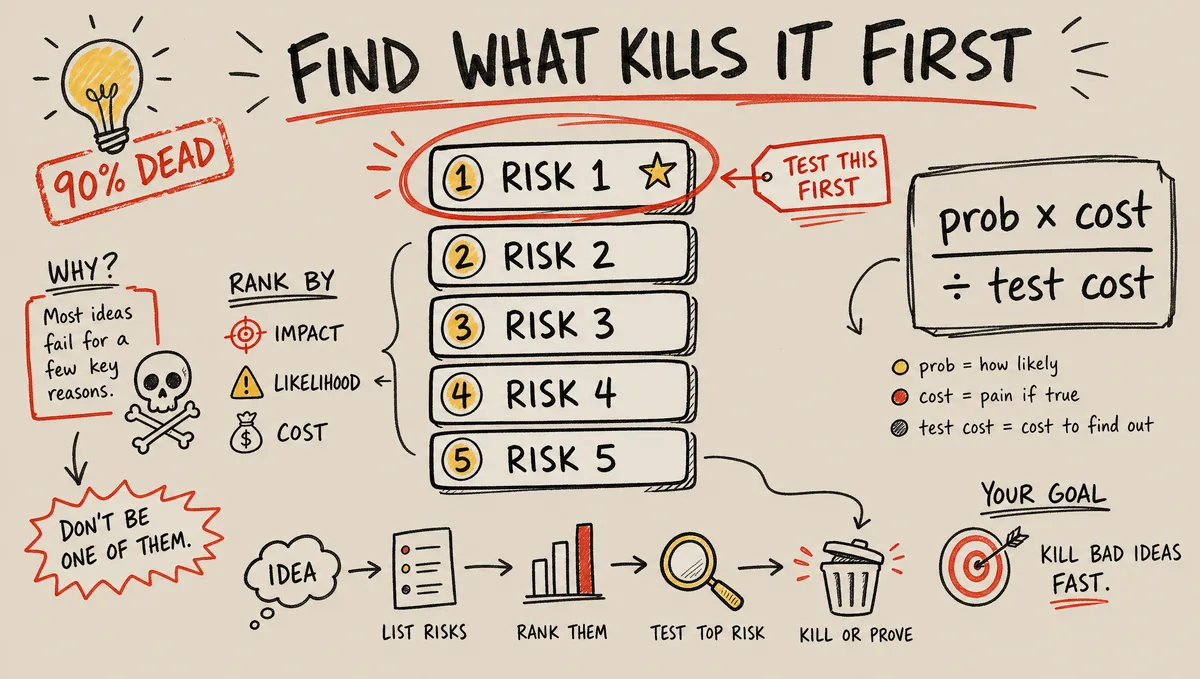
Find the assumption that would kill the idea, and test that — not the whole product. Zamesin's framing: the goal of launching a new product is not to launch it, it's to validate the riskiest assumption. A fresh idea, he says, is already 90% dead — you just don't yet know what will kill it. The MVP exists to find that out cheaply, before you've sunk a month into the wrong thing.
Every new product stands on a stack of unproven assumptions, each carrying some risk. Rank them with a simple formula: probability the assumption is wrong, times the cost if it is, divided by the cost to test it. The one at the top is what your MVP should attack first. AI is genuinely useful here — it'll generate the candidate risks fast — but you do the ranking, because the model can't feel which mistake actually ends you.
- How to validate your app idea (before you build)
The deeper validation pass — interviews, the wedge, and killing the idea on purpose before code.
How do you do market research with AI?
Paste your idea into ChatGPT or Claude with a prompt that asks it to map the market the way jobs-to-be-done does: who the segments are, the job each one is hiring the product for, and who the existing competitors are. In minutes you get a structured map — for the photoshoot idea it surfaced job-seekers refreshing a résumé, daters, personal-brand experts, and content creators, each with a different underlying job.
Treat the output as a hypothesis generator, not an oracle — Zamesin is explicit that what the model returns is incomplete and not precise, so you don't bet expensive decisions on it. What it's great at is showing you, fast, how the market might be shaped so you can react. The real work is the next step: choosing which of those segments to actually chase.
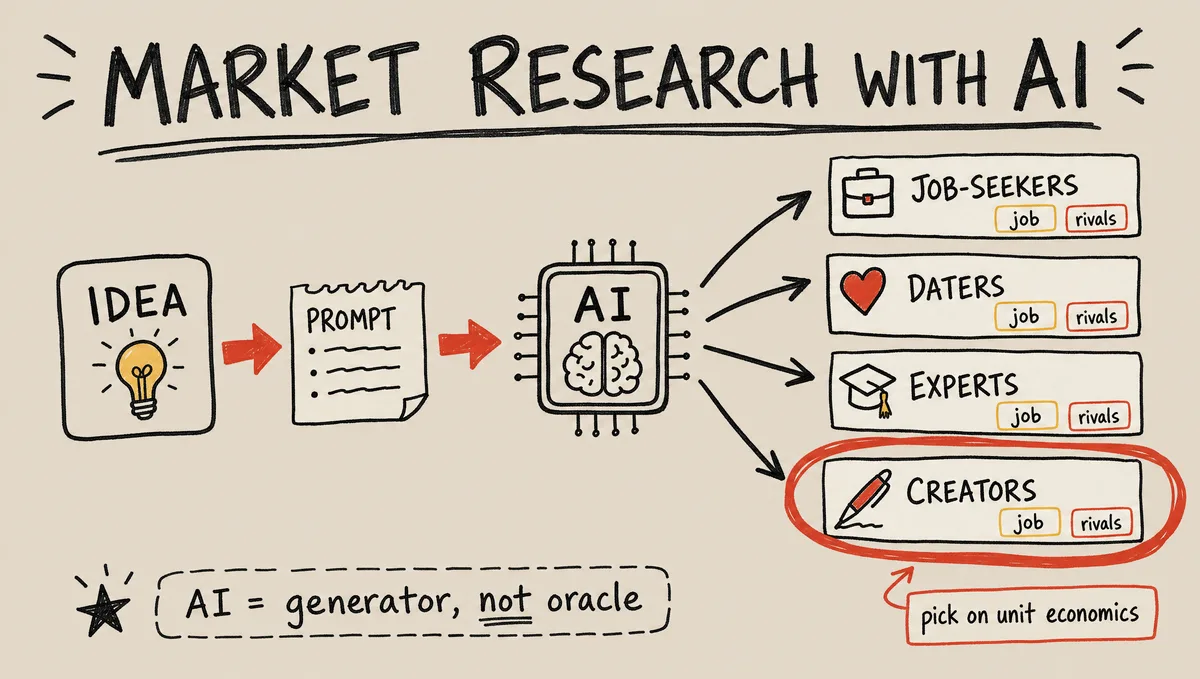
How do you pick the right customer segment?
Pick on unit economics, not on which segment sounds nicest. The live pivot is the whole lesson: the first instinct was 'people who need a quick résumé photo,' but that's a one-time job — the user gets their photos and never comes back, which leaves you almost no margin to acquire them. So they dropped it. Dating got dropped too, for the same reason plus heavy competition from free filters.
The fix is to chase a frequent, recurring job. Who needs new photos of themselves constantly? Content creators and micro-influencers. Same product, but a segment whose job repeats — which is what makes the numbers work. The rule underneath it: if a segment already pays a lot for a job, doing that job dramatically cheaper is itself a value proposition. Choose the segment whose job comes back.
How do you write a PRD with AI?
Don't ask the AI to write the spec — make it interview you first. The move from the session: drop your chosen segment, its job, and your ranked risks into a single context file, then tell the model something like, 'You're the best product expert in the world. Ask me up to 10 questions, and from my answers write detailed product requirements so the MVP tests these riskiest assumptions.' The cap on questions keeps it focused; answering them is where your judgment goes in.
Then scope ruthlessly. The MVP landed on a web app (no time for native), three uploaded photos, a short list of styles, and one Stripe payment — everything that didn't test the core assumption got cut. Have the model save the result to a file you can edit. The PRD isn't documentation; it's the leash that keeps the coding agent building the one thing you're trying to prove.
- How AI agent memory works (context files like CLAUDE.md)
Why the context file you hand the model — segment, risks, rules — is what makes the output good.
Cursor or Claude Code: which should you use to build the MVP?
In this build they did different jobs: Cursor as the editor you read and tweak files in, and Claude Code as the agent that actually writes, tests, and ships the app. Zamesin moved the heavy lifting to Claude Code for a blunt reason — cost and limits. He says he burned $400 in Cursor's agents in two days, then switched to a flat Claude plan and stopped hitting walls. He also leans on Claude Code's plugins, and the fact that it can open a browser and test its own work.
The supporting cast: Warp as a terminal that lets you paste screenshots straight to the agent when you're debugging, and Wispr Flow to dictate to the model by voice instead of typing. If you've never coded, the honest on-ramp is a tool like Lovable to feel the loop, then graduate to Cursor plus Claude Code when it starts holding you back. Pick the agent with the limits you can afford to run all day.

- The best vibe coding tools, ranked
A maker's breakdown of Claude Code, Cursor, Lovable and the rest — what each is actually good at.
How do you vibe-code, deploy, and debug it?
Let the agent build and test itself, and treat the code as a black box. The agent generates the app, runs a dev server, and opens a browser to check its own flow. When the first build broke — and it did, repeatedly — the debugging method was simple: tell it to read the logs, find the problem, and add more logging if there isn't enough. When the browser hung, he screenshotted the error and pasted it straight into the agent. You don't read the stack trace; you hand it back.
For shipping, put your deploy rules in the agent's context file: it can commit, run migrations, and deploy over SSH itself instead of asking you to. In the demo it deployed to a cheap server, wired Stripe Checkout with a test price and a webhook, and bought a domain. Be honest about the messy parts too — the domain didn't resolve in time and they tested via the server's IP, and the Stripe flow was exercised with a test card, not a real customer. A shipped MVP isn't a sale; it's a test that's finally ready to run.
How long does it take, and what does it cost?
The build in the session took about two hours to go from one sentence to a deployed, payment-wired MVP — fast because the thinking was front-loaded, not because the tools are magic. Your first run will be slower; that's fine. The clock that matters isn't build time, it's how quickly you get to a real signal from a real user.
Costs, as cited in the session: a flat Claude plan around $200/month for serious building (he notes the cheaper tiers run out fast), about $12/month for voice dictation, and a small server in the $5–8/month range. Google's AI Studio handed out roughly $300 in free image-model credits to start. None of it is free, but it's a rounding error next to what 'build an MVP' cost five years ago — the expensive part now is your attention, not your infrastructure.
What happens after you ship?
Shipping is the start of the test, not the end of the work. The MVP exists to put your riskiest assumption in front of real people — so the moment it's live, the job switches from building to distribution. A deployed app with no users proves nothing; the assumption only gets tested when strangers try it and either pay, return, or bounce.
So point the same energy at getting the first users, then read what they do. If the segment you picked on unit economics actually comes back, you have something; if not, you've learned it in a weekend instead of a quarter — which was the entire point.
- How to get your first users
The free channel map for getting a just-shipped MVP in front of real people.
- Future-proof skills: be the builder-distributor
Why the person who can both ship and distribute, solo, is the one who wins now.
- List your AI app on Vibedonalds
Free after a quick review — a niche, crawlable directory for vibe-coded and AI-built products.
Frequently asked questions
- How do you build an MVP with AI?
- Run one loop end to end: turn the idea into AI market research, find the riskiest assumption, have AI write a PRD that tests it, then vibe-code and ship the smallest version with a coding agent like Claude Code. The model does the research, spec, and code; you make the judgment calls between steps. A focused build can take a couple of hours.
- What is the riskiest assumption test?
- It's choosing to validate the single assumption most likely to kill your idea, instead of building the whole product. Rank each assumption by probability it's wrong, times the cost if it is, divided by the cost to test it. The top one is what your MVP should attack first — the goal of launching isn't to launch, it's to learn that fast.
- How do you do market research with AI?
- Paste your idea into ChatGPT or Claude and ask it to map the market like jobs-to-be-done: the segments, the job each hires the product for, and the competitors. You get a structured map in minutes. Treat it as a hypothesis generator, not an oracle — it's incomplete, so use it to see the shape of the market, then judge it yourself.
- Cursor or Claude Code — which is better for building an MVP?
- In this build they did different jobs: Cursor as the editor for reading and tweaking files, Claude Code as the agent that writes, tests, and deploys. The deciding factor was cost and limits — a flat Claude plan ran all day where Cursor's agents burned through budget fast. For most makers, the agent with affordable limits wins.
- How do you write a PRD with AI?
- Make the model interview you before it writes. Give it your segment, its job, and your ranked risks in one file, then tell it to ask up to ~10 questions and write requirements so the MVP tests those risks. Then cut scope hard — keep only what tests the core assumption — and save it to a file you can edit.
- How long does it take to build an MVP with AI?
- The session went from one sentence to a deployed, payment-wired MVP in about two hours, because the research and risk thinking were front-loaded before any code. Your first run will be slower. The number that matters isn't build time — it's how fast you get a real signal from a real user.
- Can you build an MVP if you can't code?
- Largely yes. The maker in the session treated the code as a black box and never read it — the agent wrote, tested, and deployed everything. If you're starting cold, a tool like Lovable lets you feel the loop, then move to Cursor plus Claude Code when it limits you. You still need product judgment; you no longer need to write the code.